
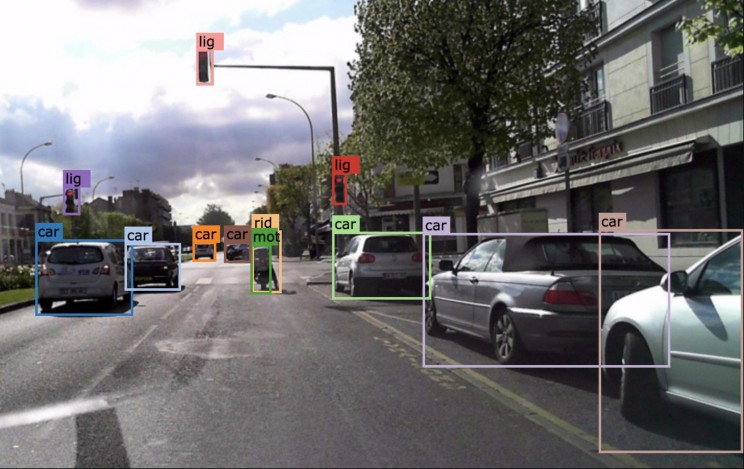

UC Berkeley hat den größten selbstfahrenden Datensatz für die breite Öffentlichkeit geöffnet. Der riesige Datensatz enthält 100.000 Videosequenzen kann von Ingenieuren und anderen in der aufstrebenden Industrie zur Weiterentwicklung verwendet werden selbstfahrende Technologien.
Sie können den Datensatz 'BDD100K' herunterladen. hier . Jedes Video im Datensatz ist bei angemessener Definition ungefähr 40 Sekunden lang 720p und 30 Bilder pro Sekunde.
Zusammen mit jedem Video geben GPS-Informationen, die von Mobiltelefonen aufgezeichnet wurden, einen Hinweis auf die ungefähre Fahrbahn. Alle Videos wurden an verschiedenen Orten in den USA gesammelt.
Der Datensatz deckt eine Reihe von Fahrbedingungen ab.
Die öffentlich zugänglichen Videos bieten eine reichhaltige Fundgrube, da sie eine Vielzahl unterschiedlicher Wetterbedingungen abdecken, von sonnig, regnerisch bis sogar trüb. Das Gleichgewicht zwischen Tag- und Nachtbedingungen wurde ebenfalls gelobt.
Zusätzlich zum Bau selbstfahrender Autos bietet der Datensatz die Möglichkeit, Fußgänger auf Straßen / Gehwegen zu erkennen. Das Video enthält mehr als 85.000 Fälle von Fußgängern, die eine solide Datenbank für diese Übung enthalten.

Der Open-Source-Datensatz wird vom Berkeley DeepDrive Industry Consortium organisiert und gesponsert, einer Gruppe, die sich der Untersuchung modernster Technologien in den Bereichen Computer Vision und maschinelles Lernen für Automobilanwendungen widmet. Berkeley machte keine Witze, als sie sagten, es sei dasgrößter jemals öffentlich verfügbarer Datensatz.
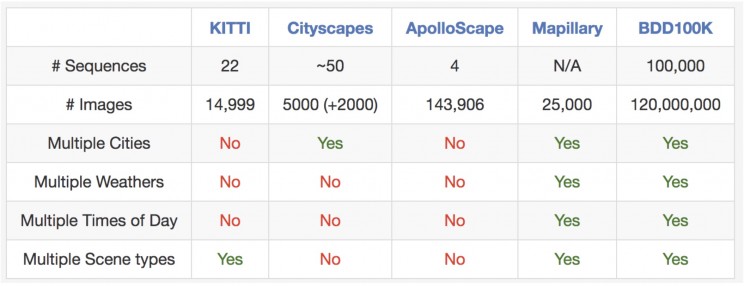
800-mal größer als Baidus Daten
Im März Baidu freigegeben ein massiver Datensatz für die damalige Zeit, aber Berkeleys Aufwand ist heute 800-mal größer als der von Baidu, 4.800-mal größer als der von Mapillary und 8.000-mal größer als der von KITTI. Die Datensätze werden voraussichtlich ein Segen für selbstfahrende Technologieentwickler sein, die daran arbeitendas Wahrnehmungssystem für autonome Fahrzeuge.
Die Nachfrage nach diesen Arten von Datensätzen war konstant hoch und es besteht kein Zweifel, dass die Großzügigkeit von Berkeley einige interessante Arbeiten hervorbringen wird. Gleichzeitig mit der Veröffentlichung des Open-Source-Datensatzes hat Berkeley drei Herausforderungen gestellt.
Überprüfen Sie die Herausforderungen im Zusammenhang mit der Erkennung von Straßenobjekten, der Segmentierung von befahrbaren Bereichen und der Domänenanpassung der semantischen Segmentierung auf ihrer Website. Die Herausforderungen werden es ermöglichen, aufkommende autonome Fahrzeugentwicklungen mit der Arbeit anderer Schlüsseldatenwissenschaftler auf diesem Gebiet zu vergleichen.
Autonomes Fahren ist einer der am schnellsten wachsenden Technologiebereiche. Von kleinen Teams an Universitäten bis hin zu großen Waffen wie Google und Uber ist jeder entschlossen, als erster die Technologie zu knacken, die fahrerlose Autos auf unsere Straßen bringt.

Selbstfahrende Autos haben kürzlich nach einer Autonomie einen schlechten Ruf bekommen Uber Auto hat einen Fußgänger getroffen und getötet, als er in Tempe, Arizona, unterwegs war. Uber hat daraufhin sein selbstfahrendes Entwicklungsprogramm unterbrochen, aber das wird voraussichtlich nicht lange dauern.
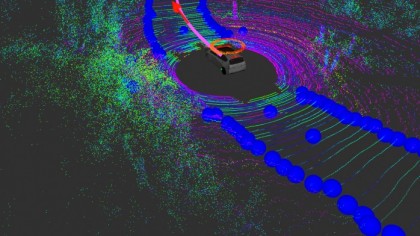
Die Veröffentlichung dieses riesigen Datensatzes bedeutet, dass Forschern und Wissenschaftlern mehr Daten zur Verfügung stehen, um selbstfahrende Autoherausforderungen zu bewältigen. Berkeley-Forscher haben dies vorgeschlagen. hinzufügen zum Datensatz in der Zukunft und erweitern Sie ihn von nur monokularen Videos um Panorama- und Stereovideos sowie andere Arten von Sensoren wie LiDAR und Radar.
Via : UC Berkeley