


In den letzten zehn Jahren sind zahlreiche webbasierte Funktionen aufgetaucht, die zu erwarten scheinen, welche Sucheinstellungen wir haben, welche Freunde wir möglicherweise in unseren Kreis aufnehmen möchten oder welche Produkte wir möglicherweise kaufen möchtenDiese technologiegetriebenen Innovationen scheinen zu wissen, was uns beschäftigt, und passen sich auf subtile oder manchmal nicht so subtile Weise an. Ein Team japanischer Forscher an der Universität Kyoto hat die Idee jedoch ein paar Schritte weiter vorangetrieben und bemerkenswerte Ergebnisse erzielt.

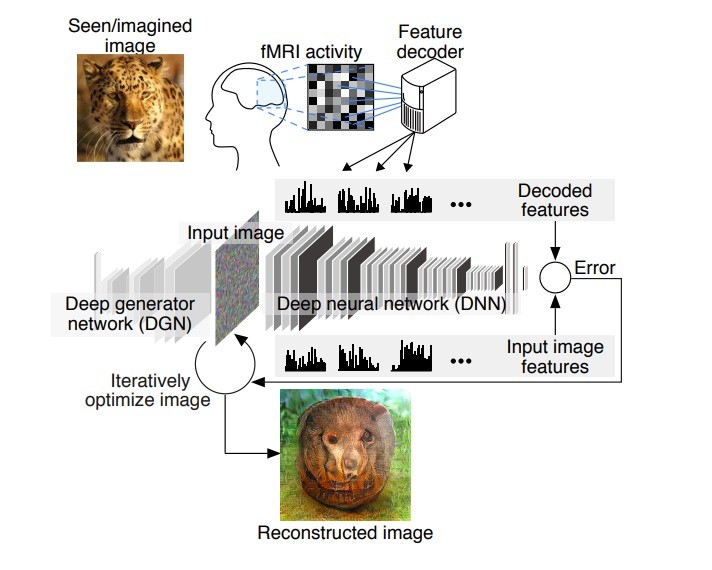
Sie entwickelten eine neue Technik, die sie als „ Tiefenbildrekonstruktion , ”und bietet die Möglichkeit, einen komplexeren Satz von Bildern zu decodieren, im Gegensatz zu ähnlichen Methoden, die auf der binären Pixeldekonstruktion beruhen. Dieser Ansatz beinhaltet im Wesentlichen„ ein Deep Generator Network DGN [das] optional mit dem [Deep] kombiniert wirdneuronales Netzwerk] DNN zur Erzeugung natürlich aussehender Bilder, bei denen die Optimierung im Eingaberaum des DGN durchgeführt wird. “Details aus dem Studie mit dem Titel „Tiefenbildrekonstruktion aus menschlicher Gehirnaktivität“ wurden Ende Dezember veröffentlicht und warten auf die Begutachtung durch Fachkollegen.
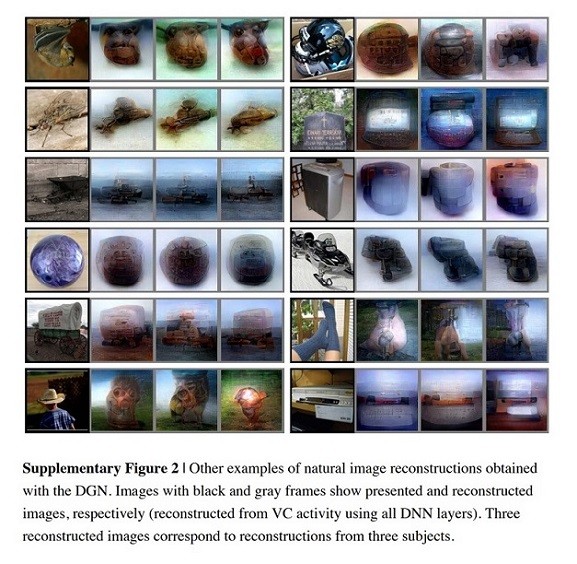
Die Untersuchung wurde über einen Zeitraum von 10 Monaten durchgeführt und begann damit, dass das Team drei Kategorien von Bildern für drei Teilnehmer erstellte, die unterschiedlich lange angezeigt werden sollten :
• Künstliche geometrische Formen
• Naturphänomene, zu denen Menschen oder Tiere gehören
• Buchstaben des Alphabets
Die Daten aus der Analyse ihrer Gehirnaktivität, die sowohl während als auch nach der Betrachtung der Bilder durch die drei Teilnehmer durchgeführt wurden, wurden über ein neuronales Netzwerk dekodiert. Und so konnten Interpretationen ihrer Gedanken generiert werden stellen Sie sich eine Art vor neuronaler Verkaufsautomat .
Professor an der Kyoto University Graduate School of Informatics Yukiyasu Kamitani der Teil des Teams war, erläutert, wie ihre Arbeit auf früheren Forschungen aufbaut: „Wir haben Methoden untersucht, um ein Bild zu rekonstruieren oder wiederherzustellen, das eine Person sieht, indem wir nur die Gehirnaktivität der Person betrachten. Unsere vorherige Methode waranzunehmen, dass ein Bild aus Pixeln oder einfachen Formen besteht. Es ist jedoch bekannt, dass unser Gehirn visuelle Informationen verarbeitet, die hierarchisch verschiedene Ebenen von Merkmalen oder Komponenten unterschiedlicher Komplexität extrahieren. “
Kamitani bespricht das Aufprall ihrer Arbeit: „Unser Gehirn verarbeitet visuelle Informationen, indem es hierarchisch verschiedene Ebenen von Merkmalen oder Komponenten unterschiedlicher Komplexität extrahiert. Diese neuronalen Netze oder KI-Modelle können als Proxy für die hierarchische Struktur des menschlichen Gehirns verwendet werden.“
Obwohl Kamitani schnell erkennt, dass mehr Arbeit in Bezug auf die Entwicklung geleistet werden muss, könnte die Technologie nach ihrer Perfektionierung den Bereich der Visualisierungstechnologie und der Schnittstellen zwischen Gehirn und Maschine möglicherweise revolutionieren, von Produktplatzierungen bis hin zur Verwendung der Methoden in Richtung Verbesserung des Versorgungsniveaus für psychiatrische Patienten durch Visualisierung ihrer Halluzinationen.