


Wenn es um die 3D-Modellschätzung aus 2D-Quellen geht, stoßen wir aufgrund eines Konflikts zwischen auf eine Ecke. Speicherkapazität und Genauigkeit . Wir benötigen einen nachhaltigen Datenfluss, um einen hohen Kontext für aufrechtzuerhalten. unsere Maschinen während für genaues Rendern mit eine hohe Auflösung erforderlich ist neuronale Vernetzung . Bisher bevorzugten Anwendungen in diesem Bereich Eingänge mit niedriger Auflösung, um insgesamt mehr Boden abzudecken. Diese Studie bringt uns einen Sprung vorwärts zu einem gemütlichen Mittelweg.
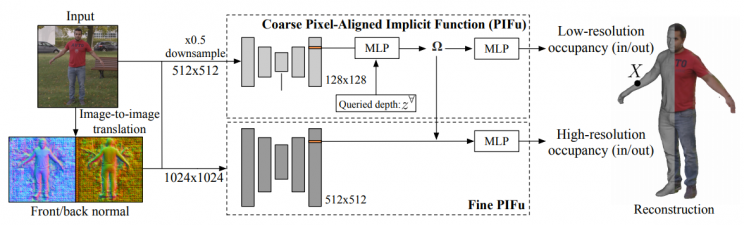
Facebook Research behebt dieses Problem mit a mehrschichtiges Analysesystem . Eine grobe Analyse nimmt das gesamte Bild auf und konzentriert sich auf die umfassende Überlegung, was wo ist. Eine zweite Ebene nimmt die Ausgabedaten von hier als Roadmap und stellt a zusammen detailliertere Geometrie mit Hilfe von Bildern mit höherer Auflösung.
SIEHE AUCH: WAS IST TIEFES LERNEN UND WARUM IST ES RELEVANTER ALS JEDERZEIT?
Diese Forschung ist nicht das einzige Unterfangen in diesem Feld . Die Digitalisierung des Menschen kann die Tür für viele Möglichkeiten in einer Vielzahl von Bereichen öffnen, wie z. medizinische Bildgebung zur virtuellen Realität, um einfach ein benutzerdefiniertes 3D-Emoji-Rendering zu erstellen. Bis heute war diese Technologie aufgrund von Einschränkungen wie der Notwendigkeit mehrerer Kameras und strengen Beleuchtungsanforderungen für die breite Öffentlichkeit begrenzt. Das Team in der Facebook-Forschung strebt eine hohe Flexibilität anRendering-System, das eine hohe Wiedergabetreue aufrechterhalten kann, wenn es um Details geht wie Falten in der Kleidung , Finger und Nuancen in Gesichtszüge .
Die bisher vorhandene Technologie
Ein bemerkenswertes Beispiel SCAPE , veröffentlicht im Jahr 2005, Stanford beschäftigt vormodellierte Netze über Bildeingaben, um 3D-Renderings zu erstellen. Diese erscheinen zwar selbst detailliert, aber nicht treu dargestellt was sie modellierten. In diesem Projekt jedoch keine 3D-Geometrie wird auferlegt Auf die Bilder wird stattdessen der geometrische Kontext auf höheren Ebenen angewendet, ohne vorzeitige Annahmen zu treffen. Dies bedeutet, dass fehlende Details von der groben Eingabe bis zur detaillierten Analyse schrittweise implementiert werden und die endgültige Bestimmung der geometrischen Eigenschaften des Modells erst am Ende erfolgtNiveau.

Die Rückseite
Aber wie steht es mit der Rückseite? Sie bleibt bei einer Einzelbildrekonstruktion unbeobachtet. Fehlende Informationen würden sicherlich verschwommene Schätzungen für Hintern und Rücken bedeuten, oder? Nun, das Team hat dieses Problem durch die Ermittlung der Normalen auf der Rückseite überwunden. wie sie es ausdrücken : "Wir überwinden dieses Problem durch Hebelwirkung Bild-zu-Bild-Übersetzungsnetzwerke um Rückseiten-Normalen zu erzeugen. Durch Konditionieren unserer mehrstufigen pixelausgerichteten Forminferenz mit der abgeleiteten Rückseitenoberflächennormalen werden Mehrdeutigkeiten beseitigt und die Wahrnehmungsqualität unserer Rekonstruktionen mit einem konsistenteren Detaillierungsgrad erheblich verbessert. "
Wenn Sie interessiert sind, haben sie ein Selbsttest-Kit bei weggelassen Google Colab obwohl fair, erfordert es eine bestimmte Menge von Technik-Know-how und ein grundlegendes Verständnis von Programmierumgebungen zum Laufen.
